Point cloud alignment with NMSAC
One approach for solving the point cloud registration problem with unknown correspondences
Abstract
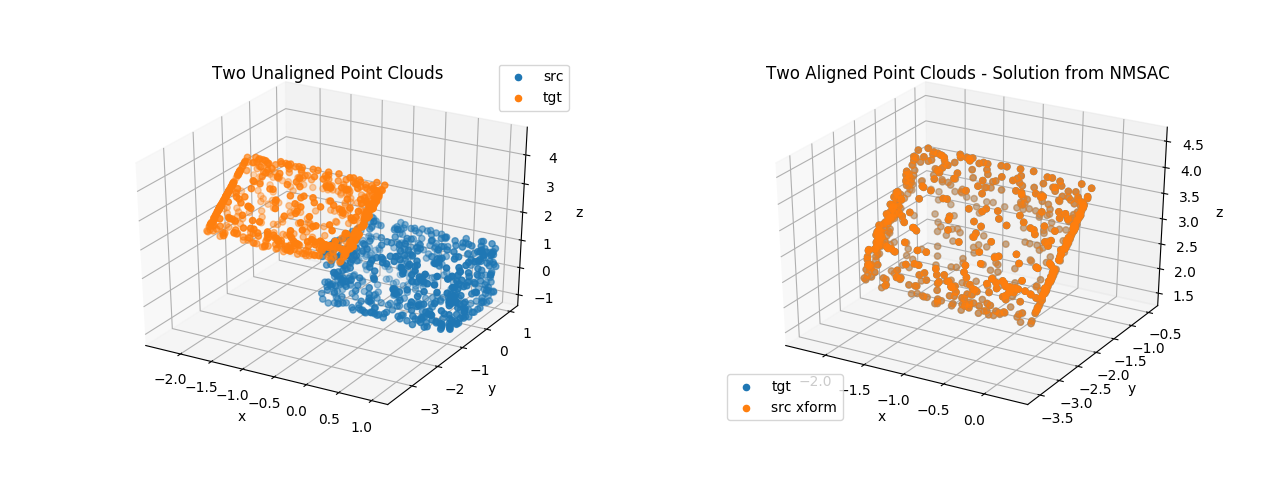
In this project writeup, I will discuss the development of NMSAC, which is an end-to-end solver for identifying the rigid motion (translation + rotation) that best aligns two point clouds: a source and target. It is furthermore assumed that there are no known correspondences between points in the source and target clouds. I will discuss the following three main aspects of NMSAC algorithm:
- Find correspondences
- Use found correspondences to coarsely align the two point clouds
- Perform fine alignment of point clouds (to account for any noise present)
Introduction
NMSAC is the culmination of 1+ years’ worth of work. I have written a few posts along the way summarizing the state of development:
- Point Cloud Registration as Optimization, Part One
- Point Cloud Registration as Optimization, Part Two
- Point Cloud Registration as Optimization, Code Implementation
- Finding Point Cloud Correspondences Using Undirected Graphs
With the exception of the third post linked above, these posts summarize the problem statement and algorithms used to solve the problem. I won’t go through these details again here. This writeup will instead be an executive summary of the project.
This project was predominately about developing skills in the following areas:
- Project organization using CMake - what is the best way to organize projects so that components can be easily included/excluded from the final build?
- Application development using Armadillo and MLPack - these API are nice considering Armadillo’s high degree of similarity to Matlab syntax and function names
- Developing simple, modular interfaces for rapid algorithm prototyping - what is the minimal information needed in a function call to setup and solve the problems considered?
- Building solid CI for maintaining project integrity - how to perform post-commit verification and integrity checks automatically?
Project Details
I have posted the project code on GitHub. The README covers steps for reproducing results, but I will go over high-level aspects of the project in the subsequent sections of this writeup to give more context.
Problem Statement
From the project’s README:
The basic workflow to achieve non-minimal sample consensus between two point clouds, src and tgt, is:
Algorithm 1: NMSAC In: src, tgt, config Out: H, homogeneous transformation that best maps src onto tgt, number of inliers, number of iterations Initialize loop: sample a set of config.N points from src (and mark the points that have been chosen) loop: sample a set of config.N points from tgt (and mark the points that have been chosen) Identify correspondences between subsampled src and subsampled tgt point sets (Algorithm 2) Identify best fit transformation that maps subsampled src points onto subsampled tgt points using correspondences found (Algorithm 3a) (optional) Perform iterative alignment of original src and tgt point sets using best fit transformation as starting point (Algorithm 3b) count inliers and update if number is higher than all previous iterations check for convergence, exit both loops if converged
What Was Achieved
- Efficient packaging of development environment using Docker
- This same development environment is used in the CI pipeline
- Demonstration of package management using modern CMake paradigms (such as generator expressions for conditional variable evaluation at build-time)
- Development of a highly-performant representation of a recent academic work (SDRSAC) presented at the world’s preeminent computer vision conference, CVPR
- Creation of a simple and elegant interface to the algorithm that is easily configured at runtime for different languages
- Currently only C++ and Python are implemented, but the pattern for building different language bindings is really simple
- Runtime configuration is specified by JSON-compliant data structure (input as a string at the function input boundary)
- This enables quick experimentation with different algorithms and their configurations without recompiling
- CI pipeline that performs pre-compile checks (e.g. linting), runtime checks (e.g. code coverage), and unit testing using circleci and GoogleTest
Concluding Remarks
Wrapping up work on this project is really bittersweet for me. I started it with a lot of excitement about possibilities for publication and collaboration with the lead author of the original SDRSAC paper. This collaboration never materialized unfortunately, so I pivoted away from pushing forward with any original research and decided to focus on how to build clean, elegant application interfaces for original research. In this regard, I think the project was a real success, as I’ve already been able to use what I’ve learned about the GoogleTest and CMake APIs to improve my work development processes significantly. I’ve really enjoyed my time developing NMSAC, but I realized that I have stopped making substantive progress and I find the work I have been doing lately to be really unsatisfying. This writeup is my “farewell” to NMSAC, however it is my sincere hope that others will take what I’ve done and find inspiration. For those whose interest has been peaked, here are some ideas for future work:
- Test NMSAC against standard 3D registration datasets (e.g. KITTI)
- Run different samples concurrently using multiple threads
- This would be really easy considering the double for-loop architecture employed for drawing and evaluating subsamples from the source and target point cloud sets
- Add new, more efficient iterative closest point (ICP) algorithms for fine-alignment
- The convention from the original SDRSAC paper to do ICP alignment after each subsampling period was adopted in NMSAC. However, this approach dramatically decreases runtime execution speed. Something else to consider would be to only do fine alignment with ICP (or a variant) once at the end of execution
Some Additional References
- Original SDRSAC paper
- List of 3D Registration Datasets
- Nice Summary of Coarse- and Fine-Alignment Methods for Point Cloud Registration